When Microsoft shipped .NET 4.6 last summer they also released a new 64-bit JIT compiler named RyuJIT. The main goal was to improve the load times of 64 bit applications, but it also allows developers to get more performance from modern processors via SIMD intrinsics. This post looks at what SIMD intrinsics are, how RyuJIT enables .NET developers to take advantage of them, some useful patterns for using SIMD in C#, and what sort of gains you can expect to see. A follow up post takes a more detailed low level look at how it works.
Note, all the code from this post is available here, on GitHub.
The Basics of SIMD (Single Instruction Multiple Data)
A CPU carries out its job by executing instructions, and the specific instructions that a CPU knows how to execute are defined by the instruction set (e.g. x86, x86_64) and instruction set extensions (e.g. SSE, AVX, AVX-512) that it implements. Many SIMD instructions are available via these instruction set extensions.
SIMD instructions allow multiple calculations to be carried out simultaneously on a single core by using a register that is multiple times bigger than the data being processed. So, for example, using 256-bit registers you can perform 8 32-bit calculations with a single machine code instruction.
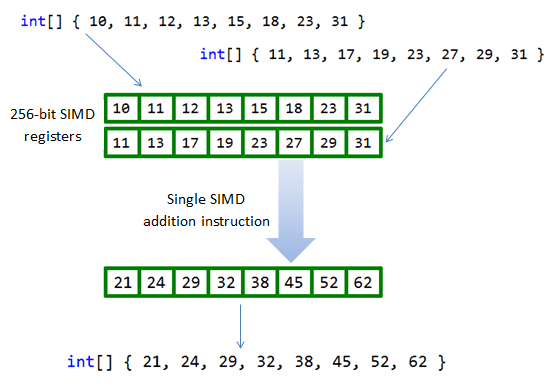
This example could give you up to an 8x speed-up, although in reality it's more likely to remove one bottleneck and expose the next, for example memory throughput. In general the performance benefit of using SIMD varies depending on the specific scenario, and in some cases it can even perform worse than simpler non-SIMD equivalent code. That said, considerable gains are achievable on today's processors if you know when and how to apply SIMD. As with all performance optimisations, you should measure the gains on a typical target machine before putting it into production. While some framework types use SIMD with minimal changes to your code, other custom algorithms bring added complexity, and so you must also consider this trade-off against the expected performance gains.
There are more details on typical expected gains below, and the follow up post looks at performance in more detail.
Just In Time (JIT) Compilation.
Developers who compile directly to native code (e.g. using C and C++) have had access to SIMD intrinsics for a while, but the problem is that you need to know at compile time which instructions are available on your target machine. You need to be certain that the instructions in your binary are available on the target processor and so you must use only the subset of instructions common to all targets, or perform run-time checks before executing certain sequences. This is where a managed language's JIT compiler is well placed.
C# (and all .NET languages) are compiled to an intermediate language called Common Intermediate Language (CIL, a.k.a. Microsoft Intermediate Language, MSIL), which is deployed to the target machine. When the application is loaded the local .NET JIT compiler compiles the CIL to native code. The upshot here is that the JIT compiler knows exactly what type of CPU the target machine has and so it can make full use of all instruction sets available to it. The new JIT compiler is, therefore, the key to making SIMD available to .NET developers.
Another advantage of accessing SIMD via the JIT compiler is that your application's performance will improve in the future without ever being rebuilt and re-deployed. When future processors with larger SIMD registers become available RyuJIT will be able to make full use them. As this post explains, it's likely that up to 2048-bit SIMD registers will available in the future. In addition, RyuJIT is likely to improve in its use of SIMD intrinsics, and this is explained further in the follow up post.
Using SIMD in C# code
The simplest and recommended way to use SIMD is via the classes and static methods in the System.Numerics namespace. Note, you need at least version 4.1.0.0 of the System.Numerics and System.Numerics.Vectors assemblies. If they didn't ship with your version of .NET then grab the System.Numerics.Vectors package from NuGet. Ensure, also, that "Optimize code" is enabled for your project, as is the default for release builds.
Within this namespace are classes that represent many common data types, for example 2D, 3D and 4D vectors, matrices and quaternions, that were written to use SIMD intrinsics whenever possible. For example, if you're working with 3D coordinates you can use Vector3 which holds three single precision floating point values representing a vector. If you add two Vector3s then (if the target processor is capable) the member-wise addition is performed using a single SIMD instruction which could give you up to a 3x speedup.
If SIMD isn't available on the target processor, or if RyuJIT isn't installed, then these types will still function correctly, just without the hardware speed-up. You should familiarise yourself with the types in this namespace and use them when appropriate.
Writing simple custom SIMD algorithms
It's fairly straight forward to write your own custom SIMD algorithms using Vector<T> where the generic type parameter can be any primitive numeric type. This class holds as many values of type T as can fit into the target machine's SIMD register. Operations on objects of this type use SIMD intrinsics whenever possible. In order to write custom algorithms you just need to know how many values of the given type you can fit into the current processor's register, and this is available in the Vector<T>.Count property.
Before executing custom SIMD algorithms such as those below you should check Vector.IsHardwareAccelerated to see if SIMD is supported on the target machine. If not it's better to avoid these algorithms as they run much slower than simpler non-SIMD algorithms, and some functions will throw NotSupportedException.
A simple example of a custom algorithm is element-wise addition of two int arrays. The below code breaks two arrays of ints into chunks of size Vector<int>.Count and sums them into a results array using SIMD:
public static int[] SIMDArrayAddition(int[] lhs, int[] rhs) { var simdLength = Vector<int>.Count; var result = new int[lhs.Length]; var i = 0; for (i = 0; i <= lhs.Length - simdLength; i += simdLength) { var va = new Vector<int>(lhs, i); var vb = new Vector<int>(rhs, i); (va + vb).CopyTo(result, i); } for (; i < lhs.Length; ++i) { result[i] = lhs[i] + rhs[i]; } return result; }
Note, the input array lengths may not be a multiple of Vector<T>.Count, and so there is a second loop to sum any remaining elements.
My machine's processor implements the AVX instruction set extension and so this addition happens four ints at a time in a in a 128-bit register. I get around a 1.9x - 2.0x speed-up relative to a simple algorithm that sums the elements individually. If I change the type to ushort then the speed-up relative to a simple algorithm is usually around 4.5x - 4.7x.
More advanced SIMD algorithms
Finally, to illustrate a more advanced custom algorithm imagine you need to perform real-time image analysis as efficiently as possible. Let's say you have a stream of 4k images (3840 x 2160) and you need to find the darkest and brightest pixel values, and the average pixel brightness for each image. This information could inform an auto-exposure algorithm and form the basis of more detailed analysis.
For clarity I'll stick with monochrome, 16 bits per pixel images (this could easily be applied to 3 colour channels). I'll show the max/min algorithm first, and then combine the average into it. Since the pixel values are 16-bit we'll use Vector<ushort>, which allows simultaneous processing of e.g. 16 values on a processor with AVX2.
Minimum and maximum of an array
To find the minimum and maximum we'll be using Vector.Min<ushort>() and Vector.Max<ushort>(). These methods take a pair of Vector<ushort>s and return the member-wise minimums and maximums in another Vector<ushort>.
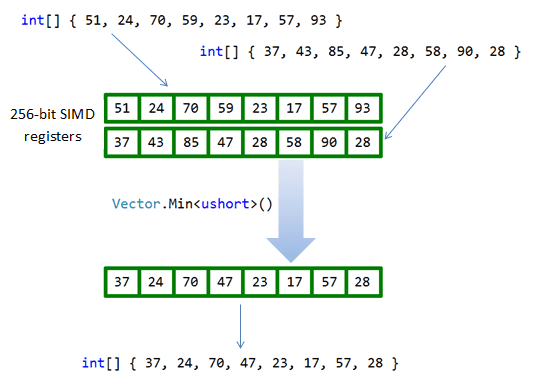
To understand how this helps to get the maximum pixel value of an image, imagine splitting the image into two sub-arrays of odd-indexed and and even-indexed pixels, finding the maximum odd and maximum even pixel, then taking the larger of these values as the maximum value of the entire image. Now, instead of splitting the image into just two sub-arrays, imagine we split it into Vector<ushort>.Count sub-arrays. We traverse the image in chunks of size Vector<ushort>.Count and use Vector.Min<ushort>() and Vector.Max<ushort>() to maintain two Vector<ushort>s of the minimums and maximums of each sub-array. Finally, compare these Vector<ushort>.Count minimums and maximums to find the minimum and maximum of the entire image. Here's the code:
public static void SIMDMinMax(ushort[] input, out ushort min, out ushort max) { var simdLength = Vector<ushort>.Count; var vmin = new Vector<ushort>(ushort.MaxValue); var vmax = new Vector<ushort>(ushort.MinValue); var i = 0; // Find the max and min for each of Vector<ushort>.Count sub-arrays for (i = 0; i <= input.Length - simdLength; i += simdLength) { var va = new Vector<ushort>(input, i); vmin = Vector.Min(va, vmin); vmax = Vector.Max(va, vmax); } // Find the max and min of all sub-arrays min = ushort.MaxValue; max = ushort.MinValue; for (var j = 0; j < simdLength; ++j) { min = Math.Min(min, vmin[j]); max = Math.Max(max, vmax[j]); } // Process any remaining elements for (; i < input.Length; ++i) { min = Math.Min(min, input[i]); max = Math.Max(max, input[i]); } }
To test the above code it was timed relative to the following non-SIMD algorithm:
public static void NonSIMDMinMax(ushort[] input, out ushort min, out ushort max) { min = ushort.MaxValue; max = ushort.MinValue; foreach (var value in input) { min = Math.Min(min, value); max = Math.Max(max, value); } }
On my own AVX capable processor the SIMD version performs about 2.5x faster than the simple non-SIMD algorithm. On a more modern processor with AVX2 the speed-up is around 4.5x - 5.5x.
Minimum, maximum and average of an array
To find the average pixel value we first need to calculate the total of all pixels in the image and then divide by the number of pixels. As with finding the minimum and maximum we could use Vector.Add<ushort>() to find the total of each sub-array, but we would first need to convert the values to ulongs to avoid arithmetic overflows. This overhead wipes out any advantage of using SIMD and such an algorithm is, in fact, much slower than a simple non-SIMD addition loop. It turns out that SIMD can't help find the average and the solution is to combine a non-SIMD algorithm into the above max/min code like so:
public static void SIMDMinMaxAverage(ushort[] input, out ushort min, out ushort max, out double average) { var simdLength = Vector<ushort>.Count; var vmin = new Vector<ushort>(ushort.MaxValue); var vmax = new Vector<ushort>(ushort.MinValue); var i = 0; ulong total = 0; var lastSafeVectorIndex = input.Length - simdLength; for (i = 0; i <= lastSafeVectorIndex; i += simdLength) { total = total + input[i] + input[i + 1] + input[i + 2] + input[i + 3]; total = total + input[i + 4] + input[i + 5] + input[i + 6] + input[i + 7]; var vector = new Vector<ushort>(input, i); vmin = Vector.Min(vector, vmin); vmax = Vector.Max(vector, vmax); } min = ushort.MaxValue; max = ushort.MinValue; for (var j = 0; j < simdLength; ++j) { min = Math.Min(min, vmin[j]); max = Math.Max(max, vmax[j]); } for (; i < input.Length; ++i) { min = Math.Min(min, input[i]); max = Math.Max(max, input[i]); total += input[i]; } average = total / (double)input.Length; }
Compared to a simple non-SIMD algorithm (i.e. the non-SIMD max/min algorithm augmented with a running total) the SIMD algorithm gives about a 1.1x speed-up on my machine, and around a 2.2x speed-up on a processor with AVX2.
The above code is quite a bit more complicated than a non-SIMD version so make sure it's well tested and, again, make sure the performance improvements measured on a typical target machine are worthwhile.
Conclusion
Since the release of .NET 4.6, developers have been able to take advantage of SIMD intrinsics without needing to know anything about the processor on which the code will be executed or invoking any specific SIMD instructions. Both the amount of complexity this adds to your code and the performance gains that can be achieved vary depending on the specific scenario. Considerable gains can often be achieved without too much effort and so it's worth knowing where and how to use SIMD. As hardware and the .NET JIT compiler improve in the future so too will the performance of SIMD algorithms written today without ever being rebuilt and re-deployed.