
Using Native Dependencies with AWS Lambda
How to use native dependencies with AWS Lambda and Functions as a Service
The AWS Lambda service offers Functions as a Service (FaaS), which means you simply supply code and AWS will provision servers and execute it in response to events. It can scale up or down in response to demand, and you only pay for the compute time you use.
FaaS offers some major benefits over other deployment techniques, but there are inevitably drawbacks, and currently the biggest one seems to be the somewhat immature developer experience. Tooling is improving, but it's got some way to go. If you stray from the happy path things can get bumpy, with documentation and error messages offering only limited help.
This post looks at how to include dependencies with your Lambda function, and in particular what you need to do if your function relies on native (binary) dependencies.
Simple Lambda Function
If your Lambda code requires only the AWS SDK library then you can edit the code directly in the AWS console.
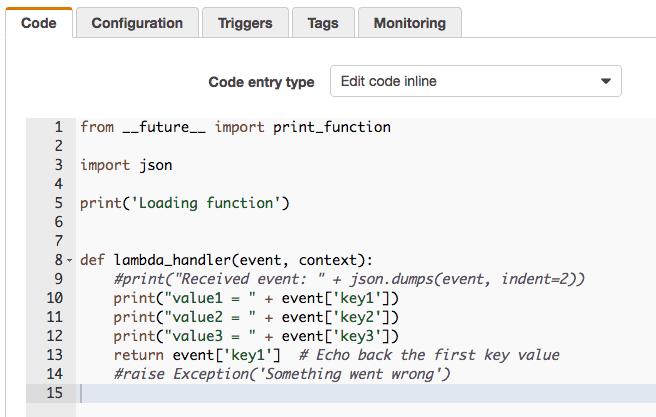
However, aside from Hello, World, this will rarely be appropriate.
Lambda Functions with Platform Agnostic Dependencies
If your Lamnda function has dependencies then you need to create a deployment package, which is simply a .zip file containing your function code along with all dependencies.
If the dependencies are platform agnostic (e.g. source code, byte code, text/config files) then this is straight forward. Be sure to check the AWS docs relevant to your function's language to make sure you structure the .zip file correctly, then upload it (either directly or via S3 if it's bigger than 10MB) and configure your Lambda function (via either the AWS console or CLI) with the entry point of the function you wish to call.
Lambda Functions with Native Dependencies
If your Lambda function relies on native, binary dependencies that are specific to the execution platform then you need to work a bit harder. The idea is the same as before in that you are providing a deployment package complete with your code and all dependencies, but you need to ensure that the native dependencies have been built for the operating system the Lambda will be executed on. If you grab native dependencies from an install on a different OS you could end up deploying e.g. .dll or .dylib files, which will be useless when the Lambda funciton is executed.
The key is to:
- Install the package that has native dependencies from within the target execution environment
- Grab the dependency files that are created from the install
- Zip them up into your deployment package
You can access the AWS Lambda execution environment by launching an EC2 instance with the Amazon Linux AMI and SSHing into it. However, an even simpler option is to run the target execution environment as a Docker container. If you use the Amazon Linux container, specifically, then you'll be well set up to test and debug any issues you may have running your code. To do so:
- Install Docker
- Run:
docker pull amazonlinuxto get the latest image version - Run the container with:
docker run -v $(pwd):/outputs -it amazonlinux. This will start the container and keep it open at the shell. It also maps the/output/folder within the container to the current working directory of the host machine, which is convenient for copying dependency files back to your development machine.
Now all you need to do is install the dependency using whatever method is suitable, bring the resultant files back via the container's /output/ folder, and zip them up into your deployment package as per the instructions for the language your Lambda function is written in.
Troubleshooting
As mentioned, the documentation tends to stick to the happy path, and error messages often offer only limited help. Remember that error messages returned by your Lambda function can be viewed via the Lambda console, and further details are logged in CloudWatch.
Keep in mind that you may be looking at an error message from the Lambda setup configuration, your code's compilation, or a runtime error. Therefore the first thing you should do is determine where the error you're looking at came from.
If the fix isn't obvious you may need to revert to some trial and error and so you should definitely shorten your feedback cycle as much as possible:
- If you're dealing with a Lambda configuration error then it may help to reduce the size of your deployment package by cutting out some/all dependencies.
- If you're dealing with a compilation or runtime error chances are you aren't seeing it in your development environment (or you wouldn't have uploaded it to Lambda). As mentioned, an upshot of the above technique is that you're now set up to isolate the issue locally without involving the Lambda infrastructure. Simply unzip and test your deployment package from within the
amazonlinuxDocker container where you can get instant feedback and find a fix.
While it may initially take a bit of effort to get your code running in Lambda, in my experience it's worth the effort as for many applications the advantages of serverless computing far outweigh the cost of any teething issues.