
Zero to Serverless car insurance - part 2
In this post, we'll be focusing on some key improvements we've made to the platform, particularly focusing on how writing less code is a good thing!
Welcome to Part 2 of our series on building from Zero to Serverless Car Insurance. In Part 1, we introduced the platform and discussed how we built an end-to-end solution using Serverless technology on AWS.
In this post, we'll be focusing on some key improvements we've made to the platform, particularly focusing on how writing less code is a good thing!

It was time to break down the Lambdalith! This had a number of key benefits for the project:
-
We no longer had to worry about maintaining our own Apollo server and could instead hand that responsibility over to AWS. Security patches and updating for new features are no longer a concern for us.
-
We could create smaller domain based services instead enabling developers to make changes with less fear of breaking other parts of the application.
-
It becomes easier to test.
-
It reduces the overall size of the Lambda function package, which reduces the duration of cold starts.
Before we dive deeper into this change we need to get one thing straight:
Serverless is not just about Lambda functions!
You could build an entire serverless application on AWS with no containers or functions at all. Our decision to adopt AppSync has enabled us to make use of more of the Serverless offerings of AWS, which leads to the next exciting phase of our project.
Going Lambda-less!
There I was, working from home during a global pandemic. We were building the customer portal for Stroll, enabling customers to login and see their policy information, download documents and submit claims.
The task was simple, execute a query to get policy data from DynamoDB. I am sure most of us have built some CRUD functionality similar to this.
Not to sound too over dramatic, but little did I know that my life was about to change forever.
To understand this life changing moment we first need to understand how AppSync works. I am not going to take too much time discussing GraphQL concepts in this post, that information is freely available online. But for context:
- GraphQL is just a schema, there are many different implementations of a GraphQL server, AppSync being one of them. I mentioned Apollo server in this series as well.
- The benefit of using GraphQL it is that you have a well defined representation of your data model that clients can query. And they only need to query the information they need.
AppSync provides the GraphQL server, authentication and data source integrations. You provide your schema and resolvers for the fields within it.
There are 2 core concepts with AppSync:
-
Data Source - A persistent storage system, e.g. a DynamoDB Table or a trigger e.g. a Lambda function
-
Resolver - Resolvers are comprised of request and response mapping templates. These templates map your GraphQL query to the appropriate request for your data source. For example if you wanted to query a DynamoDB table, your request mapping template would transform the GraphQL query into a DynamoDB query.
So if we jump back to our updated diagram, each of these Lambda functions (the orange icons) are configured as an individual data source in AppSync.

Up until this point we had been using Lambda Data Sources exclusively for our AppSync API. Every time a GraphQL query was executed, AppSync was invoking Lambda functions to get the data it needed.
But AppSync is so much more powerful than this! You can resolve data directly from various sources, including DynamoDB.
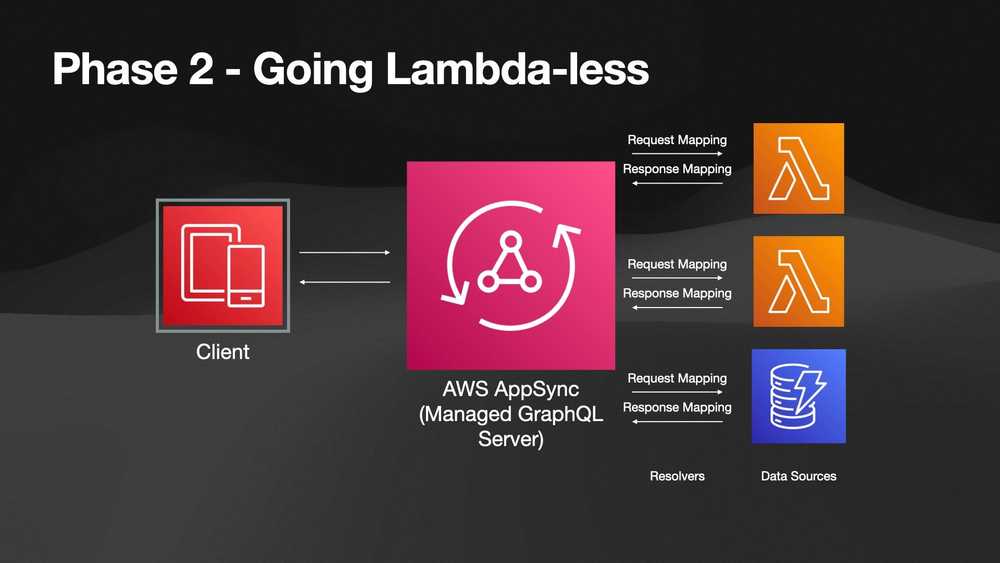
I was able to build the various queries needed for the customer portal without having to invoke a single Lambda function or write any “code” to make it happen.
Because we were now using two managed services (AppSync + DynamoDB) we were able to offload the gluing of these two services together into configuration rather than code. This is a good thing, instead of spending time writing “glue” code, we can instead write the code that matters to our customers, the code that is going to help them have some unique selling points in their marketplace.
Not only did this approach get rid of some code for us (Remember code is a liability). It also had a nice added benefit of being incredibly fast!
No Lambda function, no cold start!
This was the life changing moment for me; Combining the two services together directly resulted in performance that I was unable to achieve through writing my own Lambda function. It was from this moment on that I started to “trust” the managed services more and really dig deep into the Serverless offerings of AWS.
Like all technology decisions, we need to look at the downsides to this decision.
The big one is you have to use VTL templates. These are used to map the GraphQL queries to, in this example, a DynamoDB query:
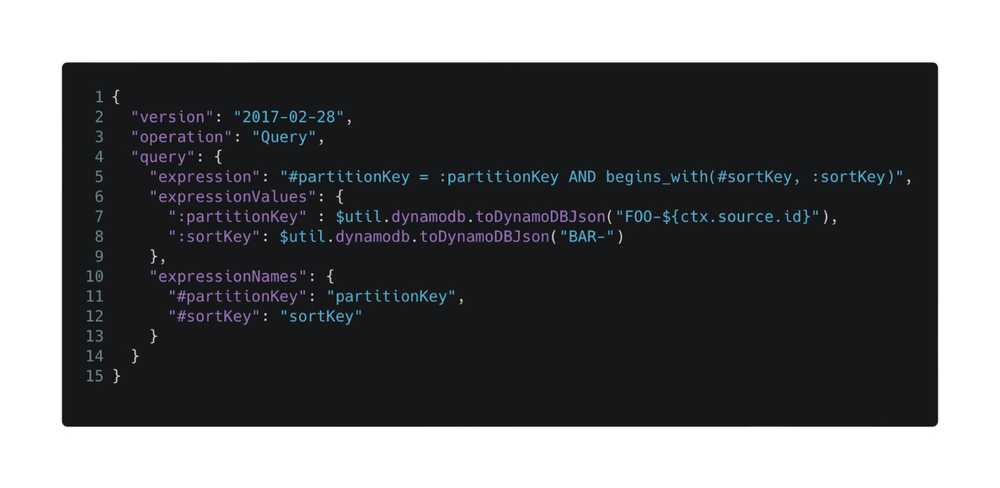
It’s a brilliant idea and because most of the managed services are using HTTP APIs, you can effectively integrate with any of them.
For whatever reason someone at AWS decided that velocity templates were the way to go when we build up the requests and responses from these direct integrations.
These are hard to unit test and have limited utility methods vs something like a TypeScript Lambda function.
Thankfully AWS have recently released JavaScript resolvers, although still quite limited, they enable developers to instead write their resolver templates using JavaScript rather than VTL. A welcome improvement and we hope to adopt these for future use cases.
In our next post we will look at how we helped the team grow in confidence when working with the Serverless architecture of Stroll.