How to test serverless applications on AWS
Testing Serverless applications can be difficult, in this post we share some real world advice on where to start!
Introduction
The topic of Serverless testing is a hot one at the moment - there are many different approaches and opinions on how best to do it. In this post, I'm going to share some advice on how we tackled this problem, what the benefits are of our approach and how things could be improved.
The project in question is Stroll Insurance, a fully Serverless application running on AWS. In previous posts, we have covered some of the general lessons learnt from this project but in this post we are going to focus on testing.
For context; the web application is built with React and TypeScript which makes calls to an AppSync API that makes use of the Lambda and DynamoDB datasources. We use Step Functions to orchestrate the flow of events for complex processing like purchasing and renewing policies, and we use S3 and SQS to process document workloads.
The Testing 'Triangle'
When the project started, it relied heavily on unit testing. This isn't necessarily a bad thing but we needed a better balance between getting features delivered and maintaining quality. Our testing pyramid triangle looked like this:
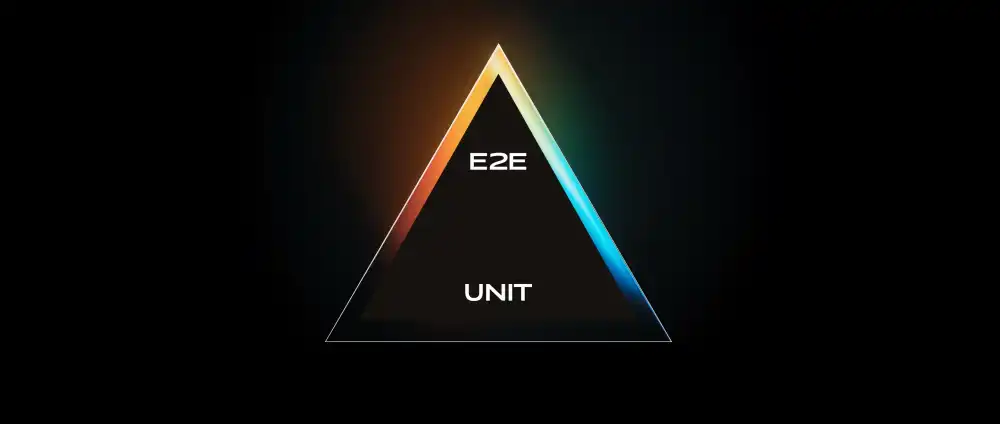
Essentially, we had an abundance of unit tests and very few E2E tests. This worked really well for the initial stages of the project but as the product and AWS footprint grew in complexity, we could see that a number of critical parts of the application had no test coverage. Specifically, we had no tests for:
- Direct service integrations used by AppSync resolvers + StepFunctions
- Event driven flows like document processing
These underpin critical parts of the application. If they stop working, people will unable to purchase insurance!
One problem that we kept experiencing was unit tests would continue to pass after a change to a lambda function but subsequent deployments would fail. Typically, this was because the developer had forgotten to update the permissions in CDK. As a result, we created a rule that everyone had to deploy and test their changes locally first, in their own AWS sandbox, before merging. This worked but it was an additional step that could easily be forgotten, especially when under pressure or time constraints.
Balancing the Triangle
So, we agreed that it was time to address the elephant in the room. Where are the integration tests?
Our motivation was simple:
There is a lack of confidence when we deploy to production, meaning we perform a lot of manual checks before we deploy and sometimes these don't catch everything.
This increases our lead time and reduces our deployment frequency. We would like to invert this.
The benefits for our client were clear:
- Features go live quicker, reducing time to market but while still maintaing quality
- Gives them a competitive edge
- Reduces feedback loop, enabling iteration on ideas over a shorter period of time
- Critical aspects of the application are tested
- Issues can be diagnosed quicker
- Complex bugs can be reproduced
- Ensures / Reduces no loss of business
Integration testing can mean a lot of different things to different teams, so our definition was this:
An integration test in this project is defined as one that validates integrations with AWS services (e.g. DynamoDB, S3, SQS, etc) but not third parties. These should be mocked out instead.
Breaking down the problem
We decided to start small by first figuring out how to test a few critical paths that we had caused us issues in the past. We made a list of how we “trigger” a workload:
- S3 → SQS → Lambda
- DynamoDB Stream → SNS → Lambda
- SQS → Lambda
- StepFunction → Lambda
The pattern that emerged was that we have an event that flows through a messaging queue, primarily SQS and SNS. There are a number of comments we can make about this:
- There's no real business logic to test until a Lambda function or a State Machine is executed but we still want to test that everything is hooked up correctly.
- We have most control over the Lambda functions, it will be easier to control the test setup in there.
- We want to be able to put a function or a State Machine into “test mode” so that it will know when to make mocked calls to third parties.
- We want to keep track of test data that is created so we can clean it up afterwards.
Setting the Test Context
One of the most critical parts of the application is how we process insurance policy documents. This has enough complexity to be able to develop a good pattern for writing our tests so that other engineers could build upon it in the future. This was the first integration test we were going to write.
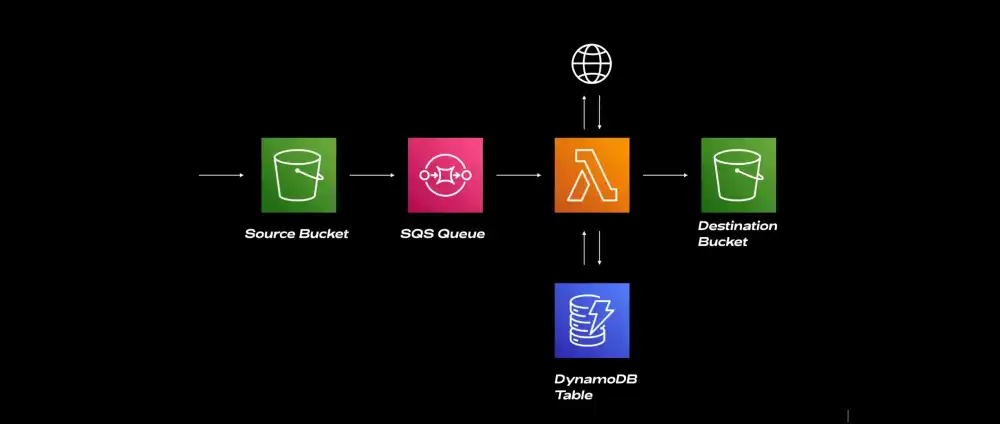
The flow is like this:
- File is uploaded to S3 bucket
- This event is placed onto an SQS queue with a Lambda trigger
- The Lambda function reads the PDF metadata and determines who the document belongs to.
- It fetches some data from a third party API relating to the policy and updates a DynamoDB table.
- File is moved to another bucket for further processing.
We wanted to assert that:
- The file no longer exists in the source bucket
- The DynamoDB table was updated with the correct data
- The file exists in the destination bucket
This would be an incredibly valuable test. Not only does it verify that the workload is behaving correctly, it also verifies that the deployed infrastructure is working properly and that it has the correct permissions.
For this to work, we needed to make the Lambda Function aware that it was running as part of a test so that it would use a mocked response instead. The solution that we came up with was to attach some additional metadata to the object when it was uploaded at the start of test case - an is-test flag:

If the S3 object is moved to another bucket as part of its processing then we also copy its metadata. The metadata is never lost even in more complex or much larger end-to-end workflows.
The Middy Touch
Adding the is-test flag to our object metadata gave us our way of passing some kind of test context into our workload. The next step was to make the Lambda Function capable of discovering the context and then using that to control how it behaves under test. For this we used Middy.
If you're not familiar, Middy is a middleware framework specifically designed for Lambda functions. Essentially it allows you to wrap your handler code up so that you can do some before and after processing. I'm not going to do a Middy deep dive here but the documentation is great if you haven't used it before.
We were already using Middy for various different things so it was a great place to do some checks before we execute our handler. The logic is simple:
- In the before phase of the middleware, check for the
is-testflag in the object's metadata and iftrue, set a global test context so that the handler is aware it's running as part of a test. - In the after phase (which is triggered after the handler is finished), clear the context to avoid any issues for subsequent invocations of the warmed up function:
export const S3SqsEventIntegrationTestHandler = (logger: Logger): middy.MiddlewareObj => {
// this happens before our handler is invoked.
const before: middy.MiddlewareFn = async (request: middy.Request<SQSEvent>): Promise<void> => {
const objectMetadata = await getObjectMetadata(request.event);
const isIntegrationTest = objectMetadata.some((metadata) => metadata["is-test"] === "true");
setTestContext({isIntegrationTest});
};
// this happens after the handler is invoked.
const after: middy.MiddlewareFn = (): void => {
setTestContext({isIntegrationTest: false});
};
return {
before,
after,
onError,
};
};Here's the test context code. It follows a simple TypeScript pattern to make the context read-only:
export interface TestContext {
isIntegrationTest: boolean;
}
const _testContext: TestContext = {
isIntegrationTest: false,
};
export const testContext: Readonly<TestContext> = _testContext;
export const setTestContext = (updatedContext: TestContext): void => {
_testContext.isIntegrationTest = updatedContext.isIntegrationTest;
};I think this is the hardest part about solving the Serverless testing “problem”. I believe the correct way to do this is in a real AWS environment, not a local simulator and just making that deployed code aware that it is running as part of a test is the trickiest part. Once you have some kind of pattern for that, the rest is straightforward enough.
We then built upon this pattern for each of our various triggers, building up a set of middleware handlers for each trigger type.
For our S3 middleware we pass the is-test flag in an object's metadata, but for SQS and SNS we pass the flag using message attributes.
A note on Step Functions
By far the most annoying trigger to deal with was Lambda Functions invoked by a State Machine task.
There is no easy way of passing metadata around each of the states in a State Machine - a global state would be really helpful (but would probably be overused and abused by people). The only thing that is globally accessible by each state is the Context Object.
Our workaround was to use a specific naming convention when the State Machine is executed, with the execution name included in the Context Object and therefore available to every state in the State Machine.
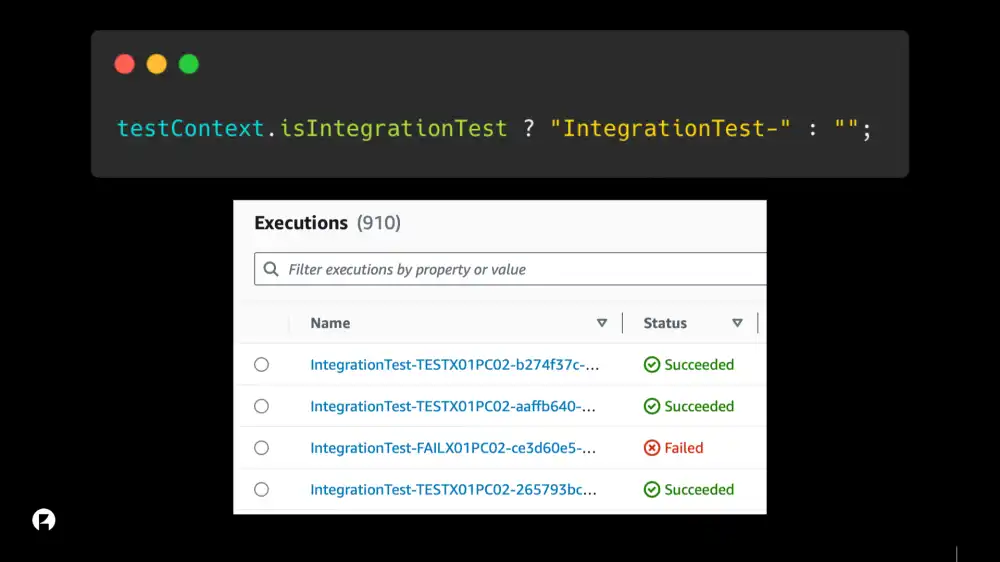
For State Machines that are executed by a Lambda Function, we can use our testContext to prefix all State Machine executions with "IntegrationTest-". This is obviously a bit of a hack, but it does make it easy to spot integration test runs from the execution history of the State Machine.
We then make sure that the execution name is passed into each Lambda Task and that our middleware is able to read the execution name from the event. (Note that $$ provides access the Context Object).

Another difficult thing to test with Step Functions is error scenarios. These will often be configured with retry and backoff functionality which can make tests too slow to execute. Thankfully, there is a way around this which my colleague, Tom Bailey, has covered in a great post. I would recommend giving that a read.
Mocking third party APIs
We're now at a point where a Lambda Function is being invoked as part of our workload under test. That function is also aware that its running as part of a test. The next thing we want to do is determine how we can mock the calls to our third party APIs.
There are a few options here:
- Wiremock: You could host something like wiremock in the AWS account and call the mocked API rather than the real one. I've used wiremock quite a bit and it works really well, but can be difficult to maintain as your application grows. Plus it's another thing that you have to deploy and maintain.
- API Gateway: Either spin up your own custom API for this or use the built in mock integrations.
- DynamoDB: This is our current choice. We have a mocked HTTP client that instead of making an HTTP call, queries a DynamoDB table for a mocked response, which has been seeded before the test has run.
Using DynamoDB gave us the flexibility we needed to control what happens for a given API call without having to deploy a bunch of additional infrastructure.
Asserting that something has happened
Now it's time to determine if our test has actually passed or failed. A typical test would be structured like this:
it("should successfully move documents to the correct place", async () => {
const seededPolicyData = await seedPolicyData();
await whenDocumentIsUploadedToBucket();
await thenDocumentWasDeletedFromBucket();
await thenDocumentWasMovedToTheCorrectLocation();
});With our assertions making use of the aws-testing-library:
async function thenDocumentWasMovedToTheCorrectLocation(): Promise<void> {
await expect({
region,
bucket: bucketName,
}).toHaveObject(expectedKey);
}The aws-testing-library gives you a set of really useful assertions with built in delays and retries. For example:
Checking an item exists in DynamoDB:
await expect({
region: "us-east-1",
table: "dynamo-db-table",
}).toHaveItem({
partitionKey: "itemId",
});Checking an object exists in an S3 bucket:
await expect({
region: "us-east-1",
bucket: "s3-bucket",
}).toHaveObject("object-key");Checking if a State Machine is in a given state:
await expect({
region: "us-east-1",
stateMachineArn: "stateMachineArn",
}).toBeAtState("ExpectedState");It's important to note that because you're testing in a live, distributed system, you will have to allow for cold-starts and other non-deterministic delays when running your tests. It certainly took us a while to get the right balance between retries and timeouts. While at times it has been flakey, the benefits of having these tests far outweigh the occasional test failure.
Running the tests
There are two places where these tests get executed, developer machines and on CI.
Each developer on our team has their own AWS account, they are regularly deploying a full version of the application and running these integration tests against it.
What I really like to do is get into a test driven development flow where I will write the integration test first and make my code changes, which will be hot swapped using CDK and then run my integration test until it turns green. This would be pretty painful if I was waiting on a full stack to deploy each time, but hot swap works well at reducing the deployment time.
On CI we run these tests against a development environment after a deployment has finished.
It could be better
There are a number of things that we would like to improve upon in this approach
- Temporary Environments - We would love to run these tests against temporary environments when a Pull Request is opened.
- Test data cleanup - Sometimes tests are flaky and don't clean up after themselves properly. We have toyed with the idea of setting a TTL on DynamoDB records when data is created as part of a test.
- Run against production - We don't run these against production yet, but that is the goal.
- Open source the middleware - I think more people could make use of the middleware than just us, but we haven't got round to open sourcing it yet.
- AWS is trying to make it better - Serverless testing is a hot topic at the moment, AWS have responded with some great resources you can find here - https://github.com/aws-samples/serverless-test-samples
Summary
While there are still some rough edges to our approach, the integration tests really helped with the issues we have already outlined and can be nicely summarised with three of the four key DORA metrics:
- Deployment Frequency - The team's confidence increased when performing deployments, which increased their frequency.
- Lead Time for Changes - Less need for manual testing reduced the time it takes for a commit to make it to production.
- Change Failure Rate - Permissions errors no longer happen in production and bugs are caught sooner in the process. The percentage of deployments causing a failure in production reduced.